
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 선형조사법
- upheap
- urlencoded
- 딥러닝
- anaconda
- 경사하강법
- 삽입식 힙
- POST
- 힙정렬
- Loss함수
- MSE
- pytorch
- 상향식 힙
- body-parser
- 이중해싱
- 해시테이블
- 선형회귀
- ML
- vsCode
- 2차조사법
- 분리연쇄법
- downheap
- nodejs
- 연결리스트
- 이중연결리스트
- bodyparser
- 알고리즘
- 개방주소법
- Today
- Total
LittleDeveloper
Pytorch로 시작하는 딥러닝 입문- 6. 인공신경망 본문
1. 머신 러닝 모델의 평가
*검증용 데이터의 필요성
하이퍼파라미터(초매개변수): 모델의 성능에 영향을 주는 매개변수들, 보통 "사용자가 직접" 정해줄 수 있는 변수
ex) 경사 하강법의 학습률(learning rate), 딥러닝의 은닉층의 수, 뉴런의 수, 드롭아웃 비율
매개변수: 가중치와 편향과 같은 학습을 통해 바뀌어져가는 변수, 기계가 훈련을 통해서 바꾸는 변수 (사용자가 결정해주는 값이 아니라 모델이 학습하는 과정에서 얻어지는 값)
->훈련용 데이터로 훈련을 모두 시킨 모델은 검증용 데이터를 사용하여 정확도를 검증하며 하이퍼파라미터를 튜닝(tuning)
*k겹 교차 검증(검증데이터, 테스트 데이터가 불충분한 경우)
2. 분류(Classification)와 회귀(Regression)
1) 이진 분류 문제(Binary Classification)
- 이진 분류는 주어진 입력에 대해서 둘 중 하나의 답을 정하는 문제.
ex) 시험 성적에 대해서 합불 판단 / 메일로부터 정상 메일, 스팸 메일인지를 판단하는 문제 등
2) 다중 클래스 분류(Multi-class Classification)
- 주어진 입력에 대해서 세 개 이상의 정해진 선택지 중에서 답을 정하는 문제
ex) MNIST Iris 데이터
3) 회귀 문제(Regression)
- 분류 문제처럼 0 또는 1이나 과학 책장, IT 책장 등과 같이 분리된(비연속적인) 답이 결과가 아니라 연속된 값을 결과로 가짐.
ex) 시험 성적을 예측하는데 5시간 공부하였을 때 80점, 5시간 1분 공부하였을 때는 80.5점, 7시간 공부하였을 때는 90점 등이 나오는 것과 같은 문제. 그 외에도 시계열 데이터를 이용한 주가 예측, 생산량 예측, 지수 예측 등이 이에 속함.
3. 지도 학습(Supervised Learning)과 비지도 학습(Unsupervised Learning)
머신 러닝은 크게 지도 학습, 비지도 학습, 강화 학습으로 나눕니다. 하지만 강화 학습은 이 책의 범위를 벗어나므로 설명하지 않습니다. 또한 이 책은 주로 지도 학습에 대해서 다룹니다.

*지도 학습 vs 비지도 학습: 레이블의 유무
*강화학습?
행동 심리학에서 나온 이론으로 분류할 수 있는 데이터가 존재하는 것도 아니고 데이터가 있어도 정답이 따로 정해져 있지 않으며 자신이 한 행동에 대해 보상(reward)를 받으며 학습하는 것을 말합니다.
- 강화학습의 개념
- 에이전트(Agent)
- 환경(Environment)
- 상태(State)
- 행동(Action)
- 보상(Reward)
게임을 예로들면 게임의 규칙을 따로 입력하지 않고 자신(Agent)이 게임 환경(environment)에서 현재 상태(state)에서 높은 점수(reward)를 얻는 방법을 찾아가며 행동(action)하는 학습 방법으로 특정 학습 횟수를 초과하면 높은 점수(reward)를 획득할 수 있는 전략이 형성되게 됩니다. 단, 행동(action)을 위한 행동 목록(방향키, 버튼)등은 사전에 정의가 되어야 합니다.
출처: https://ebbnflow.tistory.com/165 [삶은 확률의 구름]
4. 샘플(Sample)과 특성(Feature)
5. 혼동 행렬(Confusion Matrix)
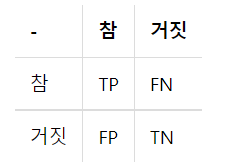
-Accuracy, Precisionn, Recall
6. 단층 퍼셉트론의 한계 => 다층 퍼셉트론의 등장
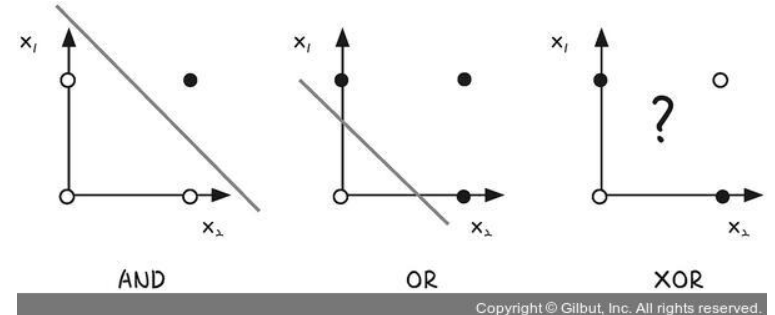
XOR 게이트는 기존의 AND, NAND, OR 게이트를 조합하면 만들 수 있음 => 층을 더 쌓기
다층 퍼셉트론과 단층 퍼셉트론의 차이는 단층 퍼셉트론은 입력층과 출력층만 존재하지만, 다층 퍼셉트론은 중간에 층을 더 추가하였다는 점입니다. 이렇게 입력층과 출력층 사이에 존재하는 층을 은닉층(hidden layer)이라 함.
즉, 다층 퍼셉트론은 중간에 은닉층이 존재한다는 점이 단층 퍼셉트론과 다름. 다층 퍼셉트론은 줄여서 MLP라고도 부릅니다.

위와 같이 은닉층이 2개 이상인 신경망을 심층 신경망(Deep Neural Network, DNN)이라고 함.
7. 역전파의 필요성?
- 모델 학습의 목적: 손실함수값이 최소가 되는 방향, 즉 손실함수가 0이 되는 방향으로 w와 b를 변화시켜야 함.
우리가 구하는 것은 하나의 w나 e가 아니라, 여러 요소가 뭉쳐진 최종결과에 대한 손실함수 값의 '현재 영향력'을 찾아내는 것이므로, 편미분을 사용하여, 각 w와 b가 가지는 '방향성'과, 각 변수들간의 '비중'에 따라서 '일정량'을 갱신해야함.
8. 활성화 함수 - 비선형 함수
즉, 선형 함수로는 은닉층을 여러번 추가하더라도 1회 추가한 것과 차이를 줄 수 없음. -> 비선형 함수 필요
1) 시그모이드
주황색 부분은 기울기를 계산하면 0에 가까운 아주 작은 값이 나옴. 그런데 역전파 과정에서 0에 가까운 아주 작은 기울기가 곱해지게 되면, 앞단에는 기울기가 잘 전달되지 않는 문제점
=>기울기 소실(Vanishing Gradient) 문제
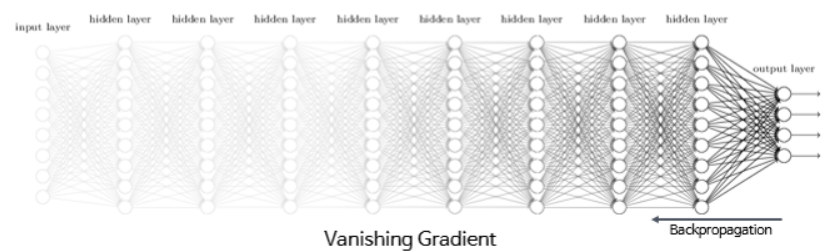
2) Tanh => 여전히 기울기 소실 문제

3) ReLU


*입력값 음수면 기울기도 음수 -> Leaky ReLU 도입
4) Softmax

-> 다중 클래스 분류에 주로 이용됨.
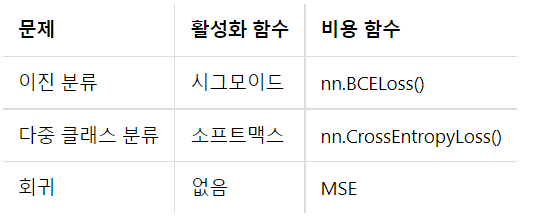
9. 과적합 방지
1) 데이터양 확보 / Data Augmentation
2) 모델 복잡도 줄이기
인공 신경망의 복잡도는 은닉층(hidden layer)의 수나 매개변수의 수 등으로 결정되므로 은닉층 수, 매개변수 줄이기
3) 가중치 규제
- L1 규제 : 가중치 w들의 절대값 합계를 비용 함수에 추가
- L2 규제 : 모든 가중치 w들의 제곱합을 비용 함수에 추가
->모두 비용 함수를 최소화하기 위해서는 가중치 w들의 값이 작아져야 한다는 특징
*Pytorch에서는 옵티마이저의 weight_decay 매개변수를 설정하므로서 L2 규제를 적용.
+ weight_decay 매개변수의 기본값은 0임. (weight_decay 매개변수에 다른 값을 설정 가능)
model = Architecture1(10, 20, 2)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-5)
4) 드롭아웃 -> 신경망의 뉴런 일부 사용하지 않음
10. 기울기 소실(Gradient Vanishing)과 폭주(Exploding)
1) 은닉층에는 되도록 ReLU 사용
2) 가중치 초기화 (가중치가 초기에 어떤 값을 가졌느냐에 따라서 모델의 훈련 결과가 달라지기 떄문)
3) 배치 정규화: 인공 신경망의 각 층에 들어가는 입력을 평균과 분산으로 정규화
'AI' 카테고리의 다른 글
| Pytorch로 시작하는 딥러닝 입문- 7. CNN (0) | 2022.03.16 |
|---|---|
| AI 실무교육 2주차 (1) Neural Network 기초 (feat. Pytorch) (0) | 2022.01.16 |
| 모두의 딥러닝 4장 경사하강법 (0) | 2022.01.09 |
| 모두의 딥러닝 3장 선형회귀법 (1) | 2022.01.08 |
| AI 실무교육 1주차 (2) 가상환경 세팅(feat. Anaconda) (0) | 2022.01.08 |



